Las teorías de los test: la TCT y la TRI


Escrito y verificado por el psicólogo Sergio De Dios González
Los test son utilizados en psicología como instrumentos de medida. Para aproximarnos un poco a concepto y sin ser del todo exactos, al igual que utilizamos el metro para medir la longitud, podríamos utilizar un test para medir la inteligencia, la memoria, la atención… Una de las diferencias entre una y otra acción sería que los test no son tan fáciles de construir, además de que tan poco son tan fáciles de aplicar.
Además, al igual que una única medición no nos permite hablar del volumen de un objeto, la administración de un único test tampoco nos permite dar un diagnóstico o proponer una intervención. Así, los test son importantes para la evaluación, pero no son un determinante de la misma.
Aquí es donde el psicólogo juega el papel más importante: de alguna manera tiene que utilizar la información que ha obtenido del test, y de otras fuentes, para dar forma a una evaluación coherente que dé paso a la planificación de la intervención. Dicho de otra manera, es a la hora de integrar los resultados de diferentes fuentes donde más se nota la calidad del profesional. Hablamos de una pericia que se consigue con el conocimiento, pero también con los años de experiencia.
Breve historia de las teorías de los test
El origen de los test suele citarse en las pruebas realizadas por emperadores chinos en los años 3000 antes de Cristo. Así, estos tenían el objetivo de evaluar la competencia profesional de los oficiales que iban a entrar a su servicio. (1)
Los test actuales tienen sus orígenes más cercanos en las pruebas realizadas por Galton (1822-1911) en su laboratorio. Sin embargo, es James Cattell el primero en utilizar el término test mental, en 1890. Dado que estos primeros test no resultaron ser demasiado predictores de la capacidad cognoscitiva del ser humano, investigadores como Binet y Simon (1905) introducen en su nueva escala tareas cognoscitivas para evaluar aspectos como el juicio, la comprensión y el razonamiento.
La escala de Binet abre una tradición de escalas individuales. Además de los test cognoscitivos, se producen grandes avances en los test de personalidad.

¿Por qué son necesarias las teorías de los test?
Ante todos los avances producidos, comienzan a desarrollarse a su vez teorías de medición (teorías de los test) que afectan directamente a los test como instrumentos que son. Con la inquietud de generar instrumentos que midan lo que queremos que midan y lo hagan con el menor error posible, aparece la psicometría. Una psicometría que va a a exigirle a todo test o instrumento de medida, que se precie de serlo, que sea válido y que sea fiable,
Recordemos que la fiabilidad se entiende como la estabilidad o consistencia de las medidas cuando el proceso de medición se repite. Dicho de otra manera, un test será más fiable cuanto mejor replique los resultados ante la medición de dos sujetos -o del mismo sujeto en oportunidades distintas- que tengan el mismo nivel en lo medido. Por su parte, la validez hace referencia al grado en que la evidencia empírica y la teoría apoyan la interpretación de las puntuaciones de los test. (2)
Así, hay dos grandes teorías de los test o enfoques cuando hablamos de analizar y construir este tipo de instrumentos: la teoría clásica de los test (TCT) y la teoría de respuesta a los ítems (TRI).
La teoría clásica de los test (TCT)
Se trata de la teoría dominante en la construcción y análisis de los test. La tazón: es relativamente fácil construir test que cumplan los mínimos que pide este paradigma. También es relativamente sencilla la evaluación del propio test en cuanto a los parámetros citados: fiabilidad y validez.
Tiene su origen en los trabajos de Spearman a principios del siglo XX. Luego, en 1968, los investigadores Lord y Novick llevan a cabo una reformulación de esta teoría y abren paso al nuevo enfoque de la TRI.
Esta teoría se basa en el modelo lineal clásico. Este modelo fue propuesto por Spearman, y consiste en asumir que la puntuación que una persona obtiene en un test, que denominamos su puntuación empírica, y que suele designarse con la letra X, está formada por dos componentes. (2)
Por un lado, encontramos la puntuación verdadera del sujeto en el test (V), y por otro, el error (e). Se expresa de la siguiente manera: X = V + e.
Spearman añade tres supuestos a esta teoría:
- Primero, definir la puntuación verdadera (V) como la esperanza matemática de la puntuación empírica: Se trata de la puntuación que tendría una persona en un test si lo hiciera un número infinito de veces.
- No existe relación entre la cuantía de puntuaciones verdaderas y el tamaño de los errores que afectan a esas puntuaciones.
- Finalmente, los errores de medida en un test no están relacionados con los errores de medida en otro test diferente.
Para culminar esta teoría, Spearman define los test paralelos como aquellos test que miden lo mismo pero con distintos ítems.
Limitaciones del enfoque clásico
La primera limitación es que, dentro de esta teoría, las mediciones no resultan invariantes respecto al instrumento utilizado. Esto quiere decir que si un psicólogo evaluara la inteligencia de tres personas con un test diferente para cada una, los resultados no son comparables. Pero, ¿Por qué ocurre esto?
Pues bien, los resultados de los tres instrumentos de medida no están en la misma escala: cada test tiene su propia escala. Para poder comparar, por ejemplo, la inteligencia de X personas que han sido evaluadas con test de inteligencia distintos, es necesario transformar las puntuaciones obtenidas directamente del test en otras baremadas.
El problema de esto es que transformando las puntuaciones en baremadas asumimos que los grupos normativos en los que se elaboraron los baremos de los distintos test son equiparables -misma media, misma desviación típica-, lo que es difícil de garantizar en la práctica. (1) Así, el nuevo enfoque de la TRI supuso un gran avance con respecto a este hecho. La TRI conseguirá así que los resultados obtenidos al utilizar distintos instrumentos estén en la misma escala.
La segunda limitación de este enfoque es la ausencia de invarianza de las propiedades de los test respecto de las personas utilizadas para estimarla. Así, en el marco de la TCT, las propiedades psicométricas importantes de los test dependen del tipo de muestra utilizada para calcularlos. Este es un hecho que también encuentra una solución, al menos parcial, en el enfoque de la TRI.

La teoría de respuesta a los ítems (TRI)
La teoría de respuesta a los ítems (TRI) nace como complemento de la teoría de los test clásica. Dicho de otra manera, la TCT y la TRI podrían evaluar un mismo test, al igual que establecer una puntuación o una relevancia para cada uno de los ítems, lo que a su vez nos podrían dar un resultado distinto para cada persona. Por otro lado, señalar que la TRI nos daría un instrumento mucho mejor calibrado, el problema es que este paradigma lleva asociado un coste mucho mayor y la participación de profesionales especializados.
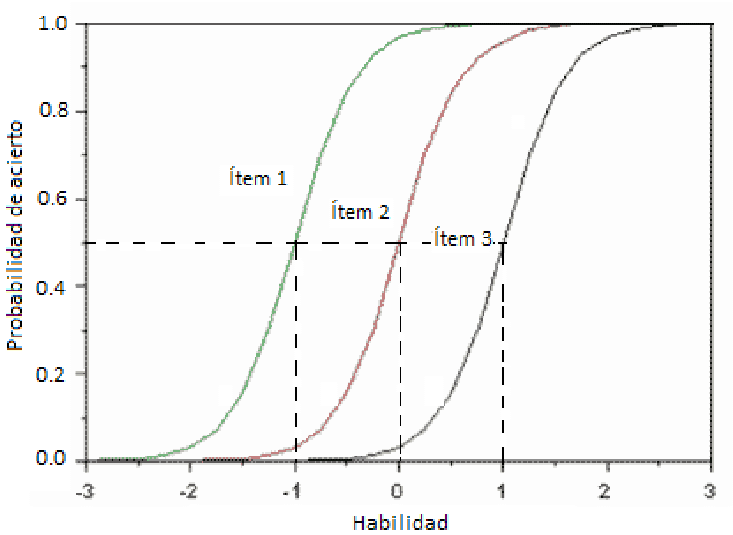
La TRI tiene varios supuestos, pero quizás el más importante nos dice que cualquier instrumento de medición debería estar en consonancia con una idea: existe una relación funcional entre los valores de la variable que miden los ítems y la probabilidad de acertar estos. Esta función se denomina Curva característica del ítem (CCI). ¿Qué suponemos entonces?
Pues algo que desde fuera puede parecer muy lógico y que la TCT no evalúa. Por ejemplo, los ítems más difíciles serían aquellos que solo contestan las personas más inteligentes. Por otro lado, un ítem que contestan todas las personas bien no nos valdría porque no tendría ningún poder para discriminar. Dicho de otra manera, no daría ningún tipo de información. Este es solo un pequeño boceto de la revolución que propone la TRI.
Para ver un poco mejor las diferencias entre un modelo de medida y otro, podemos tomar como referencia la tabla de José Muñiz (2010):
Tabla 1. Diferencias entre la TCT y la TRI (Muñiz, 2010)
| Aspectos | TCT | TRI |
| Modelo | Lineal | No lineal |
| Asunciones | Débiles (fáciles de cumplir por los datos) | Fuertes (difíciles de cumplir por los datos) |
| Invarianza de las mediciones | No | Sí |
| Invarianza de las propiedades del test | No | Sí |
| Escala de las puntuaciones | Entre 0 y la máxima en el test | Infinito |
| Énfasis | Test | Ítem |
| Relación ítem-test | Sin especificar | Curva característica del ítem |
| Descripción de los ítems | índices de Dificultad y de Discriminación | Parámetros a, b, c |
| Errores de medida | Error típico de medida común para toda la muestra | Funciones de Información (varía según el nivel de aptitud) |
| Tamaño Muestral | Puede funcionar bien con muestras entre 200 y 500 sujetos aproximadamente | Se recomiendan más de 500 sujetos |
Así es como se relacionan ambas teorías de los test. Aunque siendo casi coetáneas, parece claro que la TRI nace como respuesta a las limitaciones o problemas que puede desarrollar la TCT. Sin embargo, parece claro que la investigación aún tiene mucho camino en este campo de la psicometría.
Los test son utilizados en psicología como instrumentos de medida. Para aproximarnos un poco a concepto y sin ser del todo exactos, al igual que utilizamos el metro para medir la longitud, podríamos utilizar un test para medir la inteligencia, la memoria, la atención… Una de las diferencias entre una y otra acción sería que los test no son tan fáciles de construir, además de que tan poco son tan fáciles de aplicar.
Además, al igual que una única medición no nos permite hablar del volumen de un objeto, la administración de un único test tampoco nos permite dar un diagnóstico o proponer una intervención. Así, los test son importantes para la evaluación, pero no son un determinante de la misma.
Aquí es donde el psicólogo juega el papel más importante: de alguna manera tiene que utilizar la información que ha obtenido del test, y de otras fuentes, para dar forma a una evaluación coherente que dé paso a la planificación de la intervención. Dicho de otra manera, es a la hora de integrar los resultados de diferentes fuentes donde más se nota la calidad del profesional. Hablamos de una pericia que se consigue con el conocimiento, pero también con los años de experiencia.
Breve historia de las teorías de los test
El origen de los test suele citarse en las pruebas realizadas por emperadores chinos en los años 3000 antes de Cristo. Así, estos tenían el objetivo de evaluar la competencia profesional de los oficiales que iban a entrar a su servicio. (1)
Los test actuales tienen sus orígenes más cercanos en las pruebas realizadas por Galton (1822-1911) en su laboratorio. Sin embargo, es James Cattell el primero en utilizar el término test mental, en 1890. Dado que estos primeros test no resultaron ser demasiado predictores de la capacidad cognoscitiva del ser humano, investigadores como Binet y Simon (1905) introducen en su nueva escala tareas cognoscitivas para evaluar aspectos como el juicio, la comprensión y el razonamiento.
La escala de Binet abre una tradición de escalas individuales. Además de los test cognoscitivos, se producen grandes avances en los test de personalidad.
¿Por qué son necesarias las teorías de los test?
Ante todos los avances producidos, comienzan a desarrollarse a su vez teorías de medición (teorías de los test) que afectan directamente a los test como instrumentos que son. Con la inquietud de generar instrumentos que midan lo que queremos que midan y lo hagan con el menor error posible, aparece la psicometría. Una psicometría que va a a exigirle a todo test o instrumento de medida, que se precie de serlo, que sea válido y que sea fiable,
Recordemos que la fiabilidad se entiende como la estabilidad o consistencia de las medidas cuando el proceso de medición se repite. Dicho de otra manera, un test será más fiable cuanto mejor replique los resultados ante la medición de dos sujetos -o del mismo sujeto en oportunidades distintas- que tengan el mismo nivel en lo medido. Por su parte, la validez hace referencia al grado en que la evidencia empírica y la teoría apoyan la interpretación de las puntuaciones de los test. (2)
Así, hay dos grandes teorías de los test o enfoques cuando hablamos de analizar y construir este tipo de instrumentos: la teoría clásica de los test (TCT) y la teoría de respuesta a los ítems (TRI).
La teoría clásica de los test (TCT)
Se trata de la teoría dominante en la construcción y análisis de los test. La tazón: es relativamente fácil construir test que cumplan los mínimos que pide este paradigma. También es relativamente sencilla la evaluación del propio test en cuanto a los parámetros citados: fiabilidad y validez.
Tiene su origen en los trabajos de Spearman a principios del siglo XX. Luego, en 1968, los investigadores Lord y Novick llevan a cabo una reformulación de esta teoría y abren paso al nuevo enfoque de la TRI.
Esta teoría se basa en el modelo lineal clásico. Este modelo fue propuesto por Spearman, y consiste en asumir que la puntuación que una persona obtiene en un test, que denominamos su puntuación empírica, y que suele designarse con la letra X, está formada por dos componentes. (2)
Por un lado, encontramos la puntuación verdadera del sujeto en el test (V), y por otro, el error (e). Se expresa de la siguiente manera: X = V + e.
Spearman añade tres supuestos a esta teoría:
- Primero, definir la puntuación verdadera (V) como la esperanza matemática de la puntuación empírica: Se trata de la puntuación que tendría una persona en un test si lo hiciera un número infinito de veces.
- No existe relación entre la cuantía de puntuaciones verdaderas y el tamaño de los errores que afectan a esas puntuaciones.
- Finalmente, los errores de medida en un test no están relacionados con los errores de medida en otro test diferente.
Para culminar esta teoría, Spearman define los test paralelos como aquellos test que miden lo mismo pero con distintos ítems.
Limitaciones del enfoque clásico
La primera limitación es que, dentro de esta teoría, las mediciones no resultan invariantes respecto al instrumento utilizado. Esto quiere decir que si un psicólogo evaluara la inteligencia de tres personas con un test diferente para cada una, los resultados no son comparables. Pero, ¿Por qué ocurre esto?
Pues bien, los resultados de los tres instrumentos de medida no están en la misma escala: cada test tiene su propia escala. Para poder comparar, por ejemplo, la inteligencia de X personas que han sido evaluadas con test de inteligencia distintos, es necesario transformar las puntuaciones obtenidas directamente del test en otras baremadas.
El problema de esto es que transformando las puntuaciones en baremadas asumimos que los grupos normativos en los que se elaboraron los baremos de los distintos test son equiparables -misma media, misma desviación típica-, lo que es difícil de garantizar en la práctica. (1) Así, el nuevo enfoque de la TRI supuso un gran avance con respecto a este hecho. La TRI conseguirá así que los resultados obtenidos al utilizar distintos instrumentos estén en la misma escala.
La segunda limitación de este enfoque es la ausencia de invarianza de las propiedades de los test respecto de las personas utilizadas para estimarla. Así, en el marco de la TCT, las propiedades psicométricas importantes de los test dependen del tipo de muestra utilizada para calcularlos. Este es un hecho que también encuentra una solución, al menos parcial, en el enfoque de la TRI.
La teoría de respuesta a los ítems (TRI)
La teoría de respuesta a los ítems (TRI) nace como complemento de la teoría de los test clásica. Dicho de otra manera, la TCT y la TRI podrían evaluar un mismo test, al igual que establecer una puntuación o una relevancia para cada uno de los ítems, lo que a su vez nos podrían dar un resultado distinto para cada persona. Por otro lado, señalar que la TRI nos daría un instrumento mucho mejor calibrado, el problema es que este paradigma lleva asociado un coste mucho mayor y la participación de profesionales especializados.
La TRI tiene varios supuestos, pero quizás el más importante nos dice que cualquier instrumento de medición debería estar en consonancia con una idea: existe una relación funcional entre los valores de la variable que miden los ítems y la probabilidad de acertar estos. Esta función se denomina Curva característica del ítem (CCI). ¿Qué suponemos entonces?
Pues algo que desde fuera puede parecer muy lógico y que la TCT no evalúa. Por ejemplo, los ítems más difíciles serían aquellos que solo contestan las personas más inteligentes. Por otro lado, un ítem que contestan todas las personas bien no nos valdría porque no tendría ningún poder para discriminar. Dicho de otra manera, no daría ningún tipo de información. Este es solo un pequeño boceto de la revolución que propone la TRI.
Para ver un poco mejor las diferencias entre un modelo de medida y otro, podemos tomar como referencia la tabla de José Muñiz (2010):
Tabla 1. Diferencias entre la TCT y la TRI (Muñiz, 2010)
| Aspectos | TCT | TRI |
| Modelo | Lineal | No lineal |
| Asunciones | Débiles (fáciles de cumplir por los datos) | Fuertes (difíciles de cumplir por los datos) |
| Invarianza de las mediciones | No | Sí |
| Invarianza de las propiedades del test | No | Sí |
| Escala de las puntuaciones | Entre 0 y la máxima en el test | Infinito |
| Énfasis | Test | Ítem |
| Relación ítem-test | Sin especificar | Curva característica del ítem |
| Descripción de los ítems | índices de Dificultad y de Discriminación | Parámetros a, b, c |
| Errores de medida | Error típico de medida común para toda la muestra | Funciones de Información (varía según el nivel de aptitud) |
| Tamaño Muestral | Puede funcionar bien con muestras entre 200 y 500 sujetos aproximadamente | Se recomiendan más de 500 sujetos |
Así es como se relacionan ambas teorías de los test. Aunque siendo casi coetáneas, parece claro que la TRI nace como respuesta a las limitaciones o problemas que puede desarrollar la TCT. Sin embargo, parece claro que la investigación aún tiene mucho camino en este campo de la psicometría.
Todas las fuentes citadas fueron revisadas a profundidad por nuestro equipo, para asegurar su calidad, confiabilidad, vigencia y validez. La bibliografía de este artículo fue considerada confiable y de precisión académica o científica.
1. Muñiz Fernández, J. (2010). Las teorías de los test: teoría clásica y teoría de respuesta a los ítems. Papeles del Psicólogo: Revista del Colegio Oficial de Psicólogos.
2. Binet, A. y Simon, T. H. (1905). Methodes nouvelles pour le diagnostic du niveau intellectuel des anormaux. L’année Psychologique, 11, 191-244.
3. Lord, F. M., y Novick, M. R. (1968). Statistical theories of mental test scores. New York: Addison-Wesley.
Este texto se ofrece únicamente con propósitos informativos y no reemplaza la consulta con un profesional. Ante dudas, consulta a tu especialista.







